Chapter 6 Working with existing Data
After learning how to get your data to be the right format and how to look at said data, it now gets down to the nitty-gritty. In this chapter we will talk about where data can come from and how to get it inside of R. For that, we will talk about different ways of reading data into R to get the right format and also some first steps that should be taken with data in order to work with it properly.
We will work with some new packages, so please make sure you have the readr package as well as the wobblynameR package, which is only available on GitHub.
To install it, you will first need the devtools package and then use it to install from GitHub:
6.1 Different types of data sources
Data collected from WEXTOR - like from many other sources - will be exported in the CSV format, which stands for comma-separated values. That means that this type of data has one row per participant and the values for each column (variable) are separated by a delimiter 5.
When our data comes from an Excel file, it will often be exported as CSV because this type of storing data is pretty efficient and uses up very little space on the disk. A more modern but also more space-consuming way of storing Excel table data is in the XLSX format (Not an acronym, just stands for "Excel Spreadsheet").
Many people use SPSS for statistical analysis and creating dataframes. These data will be stored in a file with the extension SAV. Generally speaking, SAV files are compatible with R. However, there are some specialties which can cause problems, such as SPSS labels. We won't go into depth on this, just know that R can sometimes recognize SPSS labelled variables as their own class, in which case the class of those variables should be corrected manually 6.
Finally, of course we can also encounter datafiles that were created in R.
In this case the will have .Rds as the file extension.
A special case of this is when data frames are included in base-R or in a package.
For example, the dataset called iris comes with R as an example dataset.
Therefore, we can run a function on it without having to load it at all:
head(iris)
# Sepal.Length Sepal.Width Petal.Length Petal.Width Species
# 1 5.1 3.5 1.4 0.2 setosa
# 2 4.9 3.0 1.4 0.2 setosa
# 3 4.7 3.2 1.3 0.2 setosa
# 4 4.6 3.1 1.5 0.2 setosa
# 5 5.0 3.6 1.4 0.2 setosa
# 6 5.4 3.9 1.7 0.4 setosaDepending on which type of data we want to work with, there are different ways of loading the data into R.
6.2 Reading in the data
There are two main ways to load data: via the "Import Dataset" menu under the Environment-tab or (only) using code and if necessary packages. In the menu, simply select the option "Import Dataset" menu under the top-right Environment-tab and use From text (readr) for csv or other text files (such as .txt). Note that this menu also offers the possibility to load data from Excel and SPSS. However, this is much easier done by just using simple commands directly in your script:
| Data Source | R command |
|---|---|
| WEXTOR (CSV) | readr::read_delim("data.csv", delim = ";") |
| Excel (XLSX) | xlsx::read.xlsx("data.xlsx", sheetIndex = 1) |
| R Data Source (RDS) | readRDS("data.Rds") |
| SPSS (SAV) | foreign::read.spss("data.sav") |
You can follow along these exact code examples if you download the seminar_data_raw data frame from GitHub and save it in the data subfolder in your R-Project. You can find it under this link: https://github.com/the-tave/psych_research_in_r/raw/main/data/PsychResearchR_data.csv.7
Use the "Import Dataset" Menu under the Environment tab in the upper right corner of R Studio. In that menu, there are different options for different operations, but for CSV files I recommend the From Text (readr) option. Then we can select our data file and choose some basic aspects of reading in that data.
One of the reasons why i prefer this option over others is that a lot of the times it will recognize the data specifications on its own, so when you have selected the data file on you computer and copy out the generated Code from the Code Preview, it will look something like this:
Generated Code
The read_delim() function needs the file path to the data file as the minimum input requirement.
There are many basic edits that can already easily be made in this function, which can also be selected in the menu.
For example, even though "csv" stands for comma-separated values these types of files sometimes use a semicolon as a delimiter.
When reading in the data, this is sometimes recognized automatically, but when the data looks a bit funky in the preview, making sure the right delimiter is selected is a solid first step.
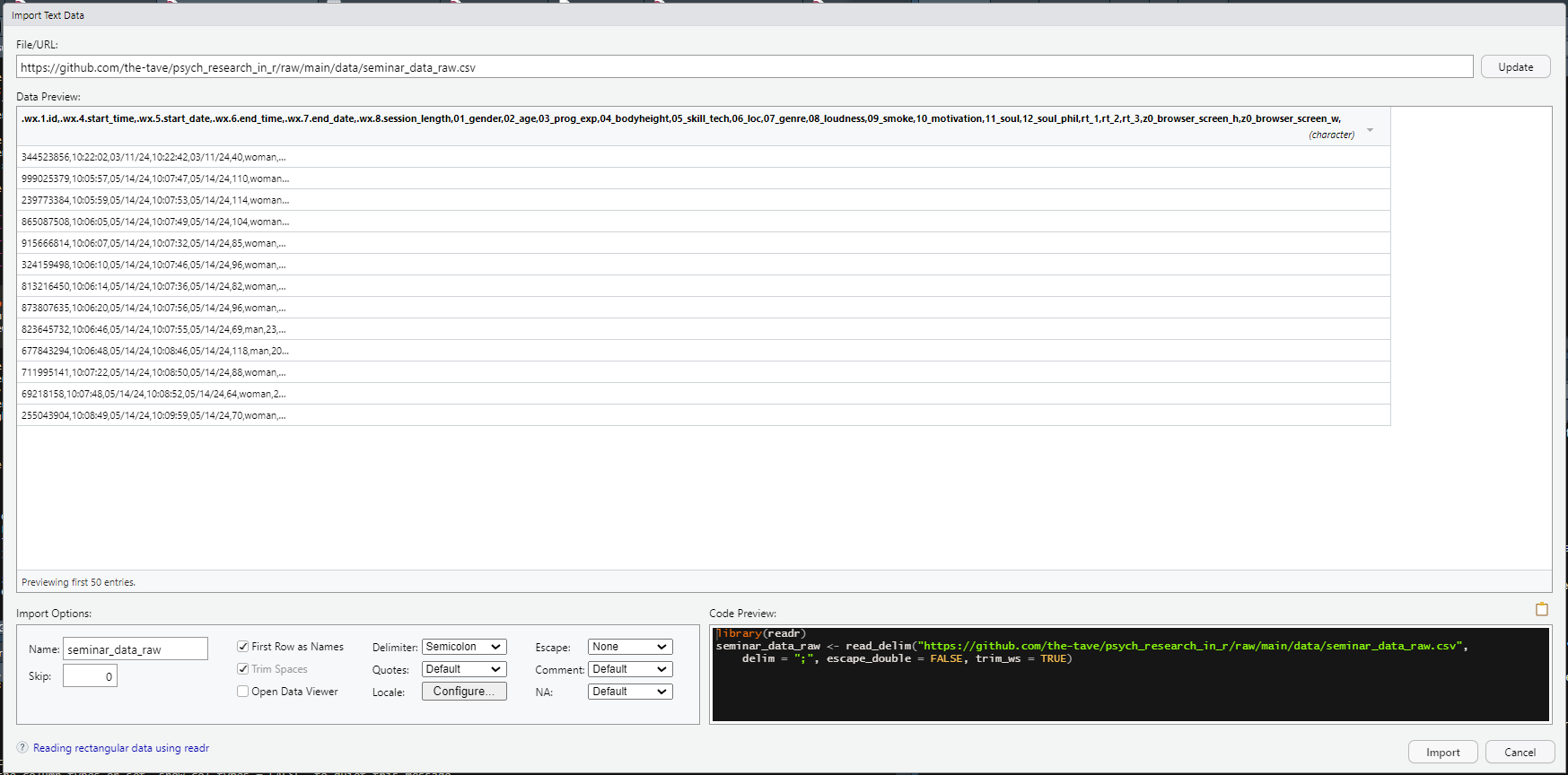
Figure 6.1: Example of wonky-looking data in the Import Dataset Menu.
Basic Edits
There are a lot more quite basic edits that we can achieve from the comfort of the Import Dataset menu.
In this case, we will make explicit some specifications that are automatically recognized, namely delim = "," - i.e. the correct delimiter, escape_double = FALSE - i.e. double quotes are not treated as a special character8 and trim_ws = TRUE - i.e. if there are white spaces in the data, they should be trimmed.
We can also specify some column types in this menu. Most columns will probably be fine staying the type they are automatically recognized as but especially some date formats are not properly recognized by R. So it makes sense to look through the data preview and do a quick visual check whether the data you see is displayed properly and the values make sense. If that check reveals that something is wrong, the little gray triangle next to the variable name offers many column types to choose from and find the one that suits your data. In our example, we will make sure that the start and end date variables are recognized as dates in the right format. For that we will choose the Date format and trigger a prompt asking for the correct format with some placeholders. When talking about dates, placeholders like m, d and y should be intuitive enough - suffice it to say that a capital Y stand for the whole year (e.g., 2024) while a small y stands for a shortened year format (e.g., 24).
Another handy column type is col_skip() which does just that - skip that specific column.
It may seem strange to exclude some data from the get-go, but some data files will end with a delimiter and R recognizes that as another column.
This is also the case for this data file from WEXTOR, which is why we will skip the last column (which is completely empty).
Moreover, we can take full advantage of both menu and script by copying the code that is generated from the menu into our script.
This automatically gives us a nice structure to start a new script for analyses with a first library command at the top (for readr) and reading in the data as a first step of analysis.
As a best practice, we will change the name of our raw data set in R to "raw".
This data set can remain untouched throughout all other data munging steps which allows us to revise edits or go back a step if something goes wrong with having to reload the data (especially with a big data set, reading it in can take a bit of time).
As a last first step, we will use the namepref0() ("name-prefix-zero") function from the rextor package to add the prefix "v" to every variable name.
There are different reasons why a consistent prefix might be useful - in this case the variable names start with a number, which can cause problems in R.
The function takes the whole data frame as input and outputs that data frame with all variables renamed, which we will save in a new data frame called "seminar".
The resulting code - the first part of which can be completely generated by the menu - looks like this:
Result
# Library commands on top
library(readr)
library(rextor)
# Generated code
raw <- read_delim("./data/seminar_data_raw.csv",
delim = ",", escape_double = FALSE,
col_types = cols(.wx.5.start_date = col_date(format = "%m/%d/%y"),
.wx.7.end_date = col_date(format = "%m/%d/%y"),
...24 = col_skip()),
trim_ws = TRUE)
# Add "v" as varname prefix to all variables
seminar <- namepref0(raw, "v")6.3 Codebook
In my experience, it is easiest to work with data where you have an idea of what to expect.
Even if you create your survey or experiment, you may forget what exactly is in which variable.
With the str() function we can get a solid overview of the data structure and with names(seminar) R will output all variable names in the seminar data frame.
When you work with someone's data, it is a good idea to either consult their codebook. It might also help you in deciding what type of analyses might make sense with which variables.
6.4 Descriptives
Next to the general overview of what is contained in the data, descriptive statistics are very useful to look at for the variables of interest. Also, in any report, we need to give our readers or listeners an overview of the data to better judge the actual meaning of the results. Basically, we need to know the sample to judge the results! A sample of e.g. 10 female psychology students probably shows different results - generally speaking - than a sample of 10 male soldiers.
Name some common descriptive statistics:
- Mean
- Median
- Mode
- Variability, Variance, Standard Deviation
- Data Visualization...
6.4.1 group_by & summarize
With the dplyr-workflow, we can easily output group statistics with the keywords: group_by() and summarize()
The code is built like any other dplyr workflow with pipes ( %>% ) in between each function.
Commonly, you will first define the name of the data frame - in the first example we will use the iris data.
Then choose the variable that should be used for grouping, such as gender or in this case Species.
Make sure that this variable is recognized as either a factor or character and try to choose a variable that has not too many groups, otherwise it might get too crowded and confusing rather than helpful.
Then you can pipe this grouped data into the summarize function and define some names for the measures that will we used in the output as well as the measure you would like to use - i.e. commonly mean() median() or sd().
You can also use n() to display the group sizes.
iris %>%
group_by(Species) %>%
summarize(m_plength = mean(Petal.Length),
med_pwidth = median(Petal.Width),
m_slength = mean(Sepal.Length),
mode_swidth = getmode(Sepal.Width),
n = n())
# # A tibble: 3 × 6
# Species m_plength med_pwidth m_slength mode_swidth n
# <fct> <dbl> <dbl> <dbl> <dbl> <int>
# 1 setosa 1.46 0.2 5.01 3.4 50
# 2 versicolor 4.26 1.3 5.94 3 50
# 3 virginica 5.55 2 6.59 3 506.5 Missing Data
In R, missing data or NAs (which stands for "Not Available") occur when some values in your dataset are absent or not recorded.
This is important to note because missing data can affect your analyses and the conclusions you draw from your research.
R treats these missing values as a special case, so they don't interfere with calculations in the same way as other values.
You can identify missing data using functions like is.na(), and there are various methods to handle them, such as removing rows with missing values or using statistical techniques to estimate them.
This can easily be done with the dplyr tools we already know and a bit of logic:
If a variable X in the data set data has one or more missing values, you can use
to filter in only those rows in the variable that as not NA (thus the !). Handling missing data properly ensures that your analysis is accurate and reliable.
Exercises
group_by & summarize
Follow the structure to group the edited seminar data by belief in the soul and output a summary with
- mean age
- mean technological skill
- mode music genre
- median volume of music
- grouped n (function n())
seminar %>%
group_by(v11_soul) %>%
summarize(m_age = mean(v02_age),
m_tech_skill = mean(v05_skill_tech),
mode_music = getmode(v07_genre),
median_volume = median(v08_loudness),
n = n())
# # A tibble: 3 × 6
# v11_soul m_age m_tech_skill mode_music median_volume n
# <chr> <dbl> <dbl> <chr> <dbl> <int>
# 1 dunno 23.4 29.4 techno 89 5
# 2 no 22 45 pop 74.5 2
# 3 yes 22.5 42 rock 67.5 6Prepare seminar data
We have read in the "seminar_data_raw" and looked at some of the basic edits that we can do easily. However, in order to be able to work with the dataset in easily in the future, we should do some more advanced edits. Specifically, we will:
- Change the date format so we get a start and end variable including time and date instead of separate date and time variables
- Remove the unnecessary original date and time variables
- Change the one missing value in
v12_soul_philto "dunno" - Rename the ID variable to
ID& session length variable tosession_length - Make our data type explicit using
as.data.frame() - Save our edited data in an R data set (
Rds) format so we can use it more easily later!
I suggest using some of the dplyr commands that were introduced in the last chapter for edits 1 through 4.
You can try to figure them out on your own and later look at the solution below.
I highly recommend you follow along with these steps, as we will use this dataset in later chapters9
seminar <- seminar |>
# 1. Change date format
mutate(start = as.POSIXct(paste(v.wx.5.start_date, v.wx.4.start_time), format = "%Y-%m-%d %H:%M:%S"),
end = as.POSIXct(paste(v.wx.7.end_date, v.wx.6.end_time), format = "%Y-%m-%d %H:%M:%S"),
.before = v01_gender) %>% # it is more efficient to have date and time together
# 2. Remove (now) unnecessary original date vars
select(-c(v.wx.4.start_time, v.wx.5.start_date, v.wx.6.end_time, v.wx.7.end_date)) %>%
# 3. Change missing value to "don't know" - in this case makes sense in context
mutate(v12_soul_phil = ifelse(is.na(v12_soul_phil), "dunno", v12_soul_phil)) |>
# 4. Rename the ID & session length variable
rename(ID = v.wx.1.id,
session_length = v.wx.8.session_length)
# 5. Make data type explicit
seminar <- as.data.frame(seminar)
# 6. Save edited data frame in Rds format
saveRDS(seminar, "./data/seminar_data.Rds")Wrap-Up & Further Resources
- Reading in data works with commands like readRDS() but also the "Import Dataset" Menu
- Use the menu for WEXTOR data to get an overview and reproducible code
- Get/ create a codebook for your data
- Always report descriptive data
-
dplyr's
group_by()andsummarize()can output grouped descriptives
...which often times is a comma, but not always! WEXTOR, for example uses semicolons.↩︎
The function calls
as.numeric()andas.factor()will suffice in most cases.↩︎If you are connected to the internet anyway you can also use this link as the file path without downloading the data first!↩︎
Escape characters are very important and very confusing. Just know that some special characters can be recognized either as plain text or as a request to do something (as code).↩︎
This is very close to real-life practice, but you can also skip it and download the Rds-file from the GitHub repository here.↩︎